Artificial Intelligence is becoming an interesting avenue of research in geology. GeoGPT and DDE are working with palaeontologists to develop LLM-augmented taxonomic keys that would help an amateur or professional palaeontologist identify a fossil. There is a big problem though: access to the highest quality descriptions of fossils is very limited because most are behind paywalls, so LLMs’ learning materials aren’t as good as they could be.
LLM-aided taxonomy
An LLM-aided taxonomy ‘key’ is text based, delivered through prompts and question/answers, working though a hierarchy of identification criteria. It delivers a set of candidate genera or species which the user can then choose from. So the system acts like an intelligent assistant. This is why we’ve called early versions of AI keys ‘Taxonomy Assistant’. Given that there are hundreds of thousands of palaeontological species, such assistance could be of great value to the amateur and professional palaeontologist alike.
How do taxonomic keys work?
In palaeontology, an identification key or taxonomic key can be in the form of a printed series of notes and instructions in a document or a chart that help you identify a fossil, perhaps at genus or species level. Identification keys are also used in many other scientific and technical fields to identify or diagnose diseases, minerals, or archaeological artifacts. Most keys provide a fixed sequence of identification steps, each with multiple alternatives, the choice of which determines the next step. A taxonomic key for fossil bisaccate pollen in chart form is shown in Fig. 1.
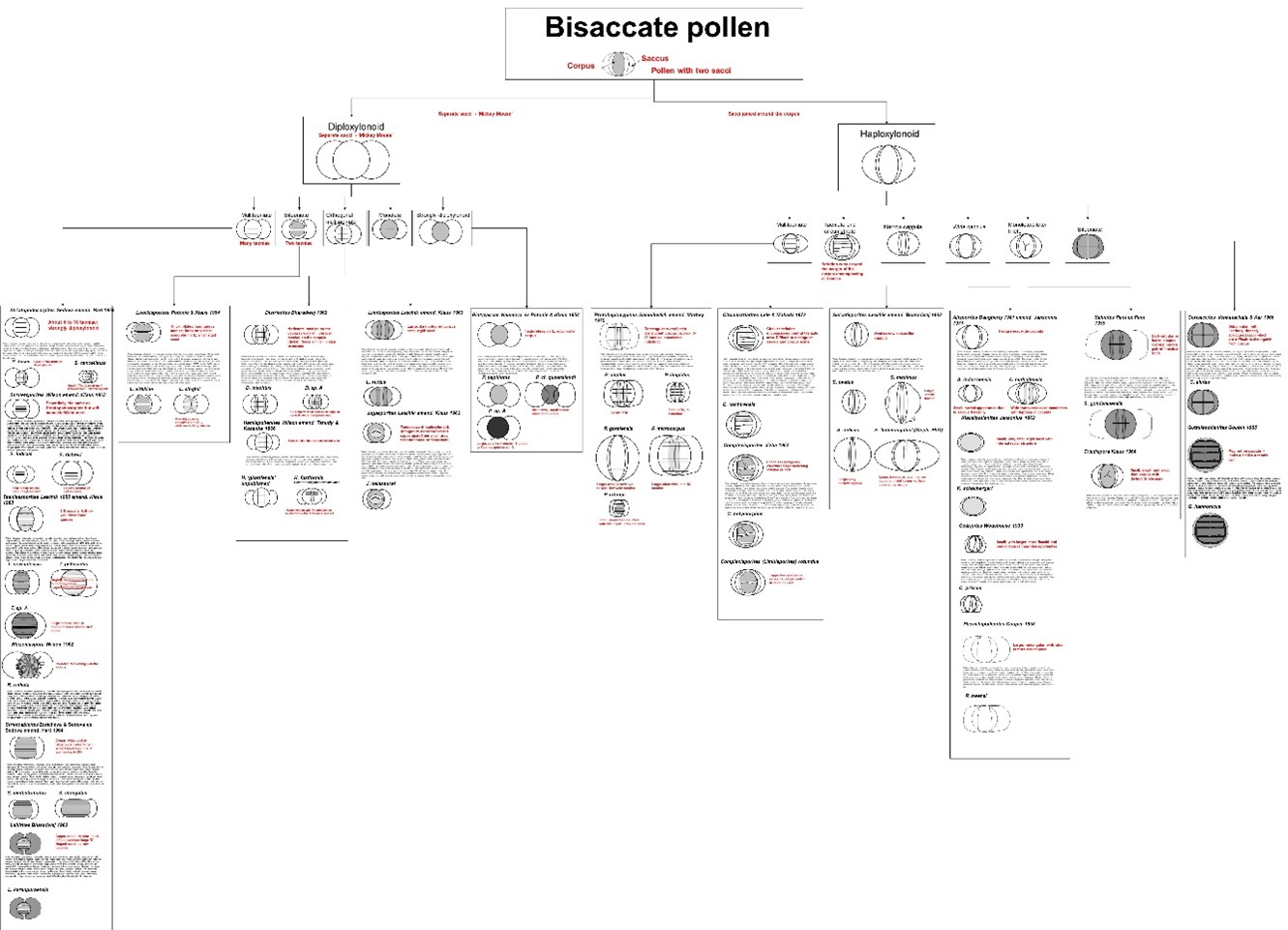
Fig. 1. A taxonomic key for fossil bisaccate pollen.
At each step, the user has to make a choice about the characters of the fossil being identified. In my particular branch of palaeontology, palynology (the study of fossil spores and pollen), there are a range of possible starting points and so the person using the key has to know something about the morphology of the range of palynomorphs that might be encountered.
One of the reasons for trying out palynology as a pilot AI project is that the ‘learning materials’ - that is the descriptions that allow genus and species level identifications - are usually clearly and consistently structured. Mostly descriptions follow a particular pattern. For example descriptions might begin with ‘…spores, radial, trilete; amb circular; laesurae distinct, with narrow lips…’. For a pollen grain (in this case a monosaccate pollen grain), the description might begin with ‘…pollen, monosaccate, radially symmetrical, trilete; amb circular’. The descriptions go on to become more detailed. The description supplies a hierarchy, in the sense that it begins with the big elements (things like shape and symmetry), and then delves deeper. So as ‘learning material’ for the LLM, many palynological descriptions allow a built-in step by step process.
An early version of a small scale Taxonomy Assistant (Fig. 2; Stephenson et al. 2024), confined to fossil spores of the Permian of the Middle East, works very well because it references a controlled, high quality corpus of species descriptions from a small number of PhD theses. But this version of Taxonomy Assistant is very narrow and serves very few practising palaeontologists. For a wider ranging, more useful Taxonomy Assistant, we need access to a wider range of high quality descriptions. This is where we come up against a problem: most high-quality descriptions, particularly of older genera and species whether in palynology or palaeontology are in pay-to-view, peer -reviewed papers. In other words, they are part of the ‘long tail’ of geoscience data.
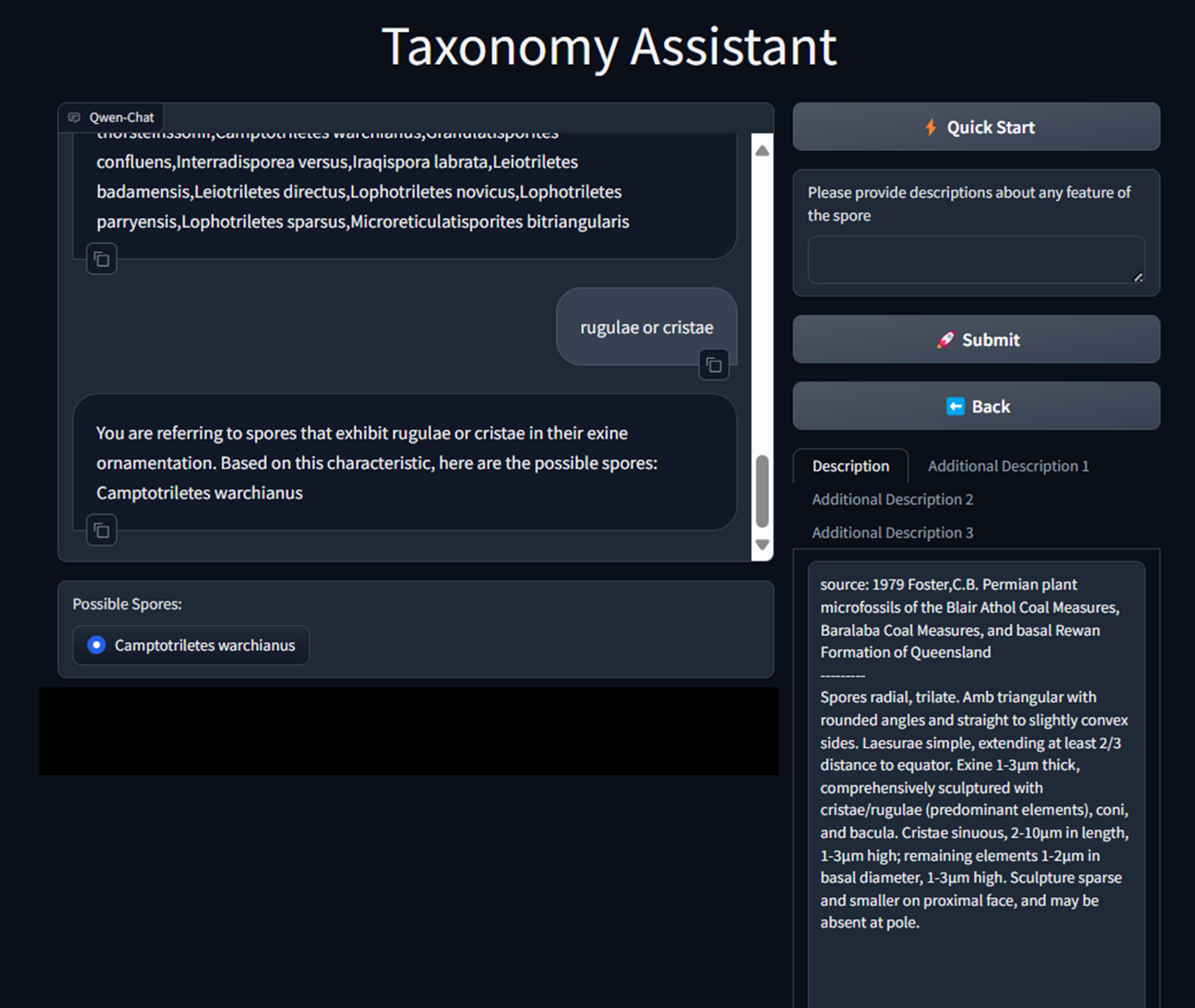
Fig. 2. A Taxonomy Assistant for the Permian spores of the Middle East
The reason that descriptions of most older genera and species are in peer reviewed papers is that for many palaeontologists and palynologists, the gold standard of publication of new species is in peer-reviewed papers, and the codes that govern the legality of publication of names for new genera and species, until recently specified publication in formal paper publications. Things have moved on a little in that the International Code of Nomenclature for Algae, Fungi, and Plants since 2012 allows publication online as long as it has an ISSN or an ISBN. But the vast bulk of fossil species and genera have been published in old papers in hardcopy journals, so even the trend towards increasing open access does not help much. Some of the smaller scientific publishers offer partial access to older papers, for example, the Journal of Paleontology offers partial access to papers before 1986 and the Palaeontology journal, published by the Palaeontological Association, offers access to papers from 1957 to 1998, but these are exceptions. Indeed the larger publishers such as Elsevier provide almost no access to older palaeontological papers. Although Elsevier’s Open Archive provides free access to archived material in 140 journals, only one is palaeontological and the material offered only spans the period from 2016 and 2019. The main Elsevier palynology journal has no free access to papers other than formal open access publications which tend to be modern. Online databases in palaeontology are very useful but tend not to contain species-level descriptions.
So what is needed?
To build species level LLM-augmented taxonomic keys all that is needed is access to descriptions and diagnoses for high quality learning materials. There are thousands of these descriptions as small packets (paragraphs) of text in the systematic or taxonomic sections of peer-reviewed papers in palaeontological journals. Access to the content of the whole paper would not be needed and these packets could be extracted fairly easily as part of a parsing process of the text. A species level LLM-augmented taxonomic key that encompasses a complete fossil group (like fossil spores or graptolites) would be an enormous asset to palaeontologists across the world, to professionals and students alike. A move toward more open access to older scientific material would also be consistent with UNESCO’s Open Science Recommendation. Platforms in palaeontology (e.g. the Paleobiology Database) already exist to help data sharing.
How can we make this happen?
References
Stephenson, M. H., Shen, C., Xiao, Z., Mao, T. 2024. Large Language Models in palynological taxonomy 27, Permophiles Issue #77 August 2024 27-30; https://permian.stratigraphy.org/files/permophiles/Permophiles%2077.pdf